如何创建品牌之制定品牌的配色方案
创建一个网站或一个品牌时,需要先确定配色方案,包括确定好主色(primary),辅色(secondary),强调色(accent)和背景色(background),以及上述颜色的不同色度(shade)、色泽(tint),色调(tone)。
创建配色方案的简要流程
- 了解色彩心理学
- 理解色彩理论
- 传递正确信息
- 创建专属调色板
- 享受劳动成果

创建一个网站或一个品牌时,需要先确定配色方案,包括确定好主色(primary),辅色(secondary),强调色(accent)和背景色(background),以及上述颜色的不同色度(shade)、色泽(tint),色调(tone)。
Meteor 1.2即将在今夏晚些时候发布,让我们先来一睹为快它有哪些新的特性:
此外,Meteor团队也公布了他们在1.2版本之后的开发路线。
具体信息请参考官方Blog文章,戳这里。


Recent research has shown that, in addition to the quality and representations of project ideas, dynamics of investment during a crowdfunding campaign also play an important role in determining its success. To further understand the role of investment dynamics, we did an exploratory analysis by applying a decision tree model to train predictors over the time series of money pledges to campaigns in Kickstarter to investigate the extent to which simple inflows and first-order derivatives can predict the eventual success of campaigns.
Read on →最近在Angular社区的原型开发者间,一种全Javascript的开发架构MEAN正突然流行起来。其首字母分别代表的是:(M)ongoDB——noSQL的文档数据库,使用JSON风格来存储数据,甚至也是使用JS来进行sql查询;(E)xpress——基于Node的Web开发框架;(A)agular——JS的前端开发框架,提供了声明式的双向数据绑定;(N)ode——基于V8的运行时环境(JS语言开发),可以构建快速响应、可扩展的网络应用。
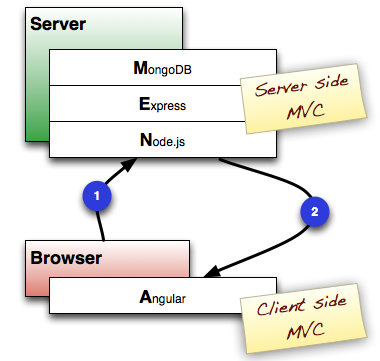
MEAN的支持者宣称,如果整个开发栈均能使用JS,必然会大大地提高效率,这一点毋庸置疑是一个很大的卖点。这样一来,开发人员(无论是前端还是后端)不仅能使用一致的数据模型,在其它方面也同样可以获得一致的编程体验。
例如,拿Mongo来说,你可以使用类JSON格式(BSON,二进制的JSON)来存储数据,然后在Express/Node中调用JSON查询语句,再将结果以JSON格式传给前端的Angular显示,这样,也自然使调试程序容易了很多。
Read on →每个应用都由两样东西构成:该应用独有的功能和所有应用共有的功能,比方说用户注册、登录、忘记密码等。而从用户的角度出发,那些独有的功能归结起来就是用户界面以及系统的行为模式。而在视觉表象之后的功能,用户并不关心,他们只期望系统能按预期运行就可以了。
前端和后端有各自的侧重点,因此往往也需要不同的技能,由不同的开发人员来负责完成。无后端(nobackend)的开发原则能够进一步解偶这些不同的侧重点,这样两边的开发人员可以更加专注于各自真正热衷的工作。
![]()
后端经常需要提供API给前端,以下是一个简单的例子,使用API进行用户登录。
1 2 | |
前端的开发人员需要负责发送上述请求并对结果进行响应,还要考虑到一些极端的情况,如失去连接或不可预知的服务器错误等。与此相反的是,无后端的设计原则则建议由前端开发人员来定义API,用前端的代码来描述后端的功能,举例如下:
1 2 3 | |
我们称此为梦幻代码(Dreamcode),因为这些代码经常是在真正的代码可运行以前就已经写好了。初一看,这样并没有多大意义,只不过是改成了发送AJAX请求并调用相应的回调函数而已,但是以这样的方式定义的API在许多方面都会更加强大:
Read on →
最近“知乎”上在热烈讨论一则传闻,说Facebook在招聘所谓的“全栈工程师”,要求应征者对开发堆栈的每个方面都有所掌握。那究竟何为 “全栈工程师”呢?从字面上来理解,全栈工程师必须熟悉开发堆栈的每一个层次,或者至少熟悉绝大多数并且对所有的软件技术有天生的热情和兴趣。
对于这样的开发者,他们非常擅长使用掌握的技术让自己的生活变得轻松,这也正是为什么Facebook会希望雇佣他们,他们用自己的脑子与热情编码, 好的产品也自然能在最短的时间呈现。那么,具体而言,一个合格的“全栈工程师”要具备哪些素质呢?
Read on →(This post is originaly published in CrowdResearch.org, link .)
\"")
We created a spatial location identification task (SpLIT), in which humans examine a 3D camera view of an environment to infer its spatial location on a 2D schematic map (e.g. a floor plan). However, the SpLIT are often difficult to automate because the identification of salient cues often requires semantic features that are challenging to recover from the image and the map, especially when the cues are ambiguous or do not provide sufficient information to pinpoint the exact location.
One natural question to ask is how one can leverage human computation to perform a typical SpLIT. In order to find the answer, we designed a study using Amazon Mechanical Turk to investigate how turkers can perform the task in two kinds of reward schemes: ground truth and majority vote, even when they were not familiar with the environment.
We carefully chose five pictures represent different levels of ambiguity, in terms of the extent to which workers could use the pre-defined markers (cues) to infer the location of the camera view.
The results are listed below: Read on →
Finally my blog gets online! I have been planing to setup my own blog for years. Well, I’m really a typical procrastinator. But anyway I make it.
Thanks to github page, which hosts my blog for free! Meanwhile I also have to give the credit to Octopress, an amazing framework of blog aware static site generator. Actually I have tried many tools before (such as Middleman, Jekyll , webgen etc.), but Octopress is the most handy one.
Read on →